
本篇笔记是一篇开发小结,总结GPS数据的接收、解析示例,以实例为基础分享一些思考过程:
GPS数据协议
常用的GPS模块大多采用NMEA-0183 协议,目前业已成了GPS导航设备统一的RTCM(Radio Technical Commission for Maritime services)标准协议。NMEA-0183 是美国国家海洋电子协会(National Marine Electronics Association)所指定的标准规格,这一标准制订所有航海电子仪器间的通讯标准,其中包含传输资料的格式以及传输资料的通讯协议。
协议采用 ASCII 码来传递 GPS 定位信息,我们称之为帧。
帧格式形如:
$aaccc,ddd,ddd,…,ddd*hh(CR)(LF)
GPS帧数据种类大致如下:
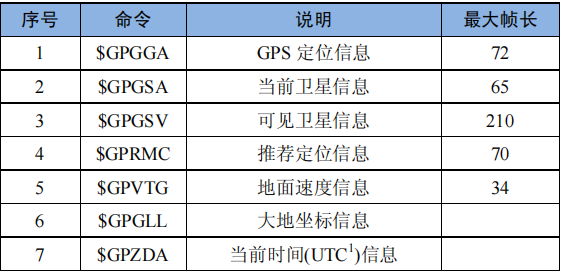
实际应用中,并不是所有数据都完全用得上,我们可以根据需要选择所需要的数据。
下面我们以$GPGGA数据为例分享接收、解析方法。
$GPGGA 语句的基本格式如下:
$GPGGA,<1>,<2>,<3>,<4>,<5>,<6>,<7>,<8>,<9>,<10>,<11>,<12>,<13>,<14>*hh<CR><LF>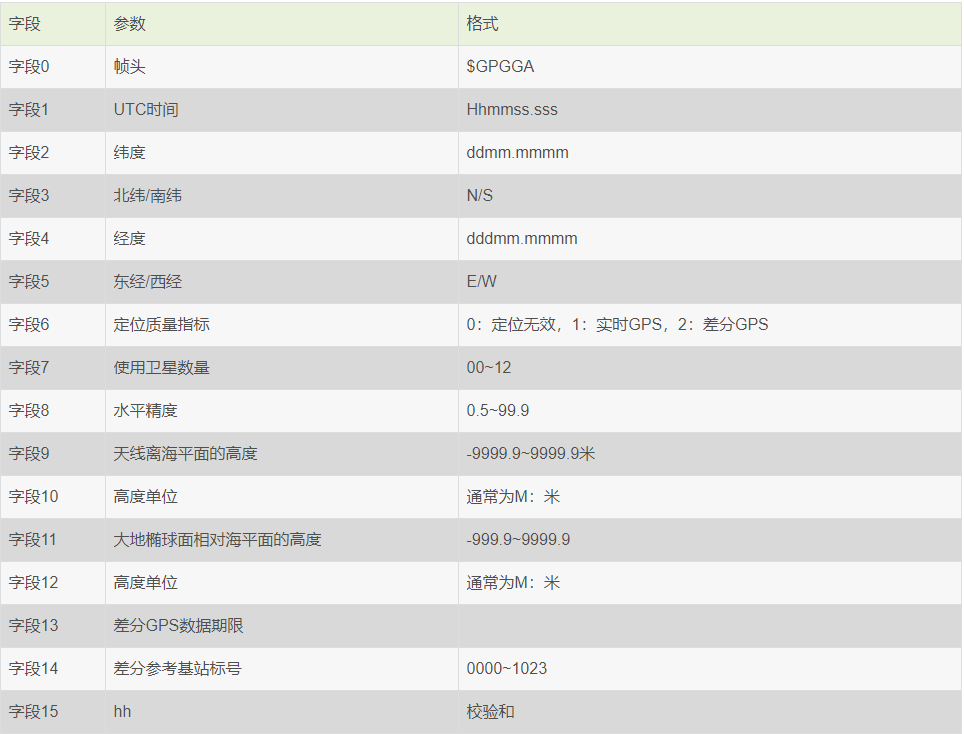
举例如下:
$PGGA,082006.000,3852.9276,N,11527.4283,E,1,08,1.0,20.6,M,,,,0000*35GPS数据接收
GPS模块使用串口通信,在解析之前当然需要先接收数据。我这里是在嵌入式Linux平台下做的接收,读串口的接口如:
int uart_read(void *data, int data_len, long time_out);下面分享我在实际应用中的三种接收方法:
方法一:粗略法
为了能快速验证数据解析、跑通整个过程,可以先使用粗略的方法获取数据。粗略法我们可以先不用考虑一帧数据的实际字节数,我们先大致设置一个用于解析的缓冲数组,如:
char rx_gps_data[512];uart_read每次读到的字节数与线程挂起时间有关,粗略法我们大致设置一个串口接收缓冲数组,如:
char uart_rx_buf[64];这时候需要把每次收到的uart_rx_buf里的内容自己拼接一下,存放到rx_gps_data中,再去做解析。
粗略法可以用于快速验证数据解析、跑通整个过程,缺点就是uart_rx_buf、rx_gps_data设置得不够合理的话可能会破坏掉大量的数据帧。
一般我都比较习惯地先快速调通整个流程,再慢慢做优化。
方法二:状态机法
上面的粗略法可能会破坏掉一些数据帧,另外,代码结构可能不够清晰。针对这些问题做改进,使用状态机来接收。一字节一字节地接收,接收完完整一帧数据之后再去做解析。
代码如:
// GGA所有状态(GGA数据示例:$GPGGA,023543.00,2308.28715,N,11322.09875,E,1,06,1.49,41.6,M,-5.3,M,,*7D)
#define GGA_STATE_START 0 // $
#define GGA_STATE_HEAD1_G 1 // G
#define GGA_STATE_HEAD2_P 2 // P
#define GGA_STATE_HEAD3_G 3 // G
#define GGA_STATE_HEAD4_G 4 // G
#define GGA_STATE_HEAD5_A 5 // A
#define GGA_STATE_DATA 6 // ,023543.00,2308.28715,N,11322.09875,E,1,06,1.49,41.6,M,-5.3,M,,*
#define GGA_STATE_CHECK0 7 // 7
#define GGA_STATE_CHECK1 8 // D
static uint16_t gga_len = 0;
static uint8_t gga_state = GGA_STATE_START;
static void gps_gga_data_get(char in_data)
{
switch (gga_state)
{
case GGA_STATE_START:
if ('$' == in_data)
{
gga_len = 0;
memset(rx_gps_gga_data, 0, GGA_DATA_MAX_LEN);
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_HEAD1_G;
}
else
{
gga_state = GGA_STATE_START;
}
break;
case GGA_STATE_HEAD1_G:
if ('G' == in_data)
{
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_HEAD2_P;
}
else
{
gga_state = GGA_STATE_START;
}
break;
case GGA_STATE_HEAD2_P:
if ('P' == in_data)
{
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_HEAD3_G;
}
else
{
gga_state = GGA_STATE_START;
}
break;
case GGA_STATE_HEAD3_G:
if ('G' == in_data)
{
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_HEAD4_G;
}
else
{
gga_state = GGA_STATE_START;
}
break;
case GGA_STATE_HEAD4_G:
if ('G' == in_data)
{
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_HEAD5_A;
}
else
{
gga_state = GGA_STATE_START;
}
break;
case GGA_STATE_HEAD5_A:
if ('A' == in_data)
{
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_DATA;
}
else
{
gga_state = GGA_STATE_START;
}
break;
case GGA_STATE_DATA:
if ('*' == in_data)
{
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_CHECK0;
}
else
{
rx_gps_gga_data[gga_len++] = in_data;
if (gga_len > GGA_DATA_MAX_LEN)
{
gga_state = GGA_STATE_START;
}
else
{
gga_state = GGA_STATE_DATA;
}
}
break;
case GGA_STATE_CHECK0:
rx_gps_gga_data[gga_len++] = in_data;
gga_state = GGA_STATE_CHECK1;
break;
case GGA_STATE_CHECK1:
rx_gps_gga_data[gga_len++] = in_data;
printf("gga data : %s\n", rx_gps_gga_data);
gga_state = GGA_STATE_START;
break;
default:
break;
}
}这样就可以完整地接收到gga数据,每次走到GGA_STATE_CHECK1状态时的rx_gps_gga_data就是完整的gga数据,这时候就可以进行解析了,可以在这一步设置一个标志变量表明gga数据已经完全接收完毕,直到数据接收完毕了才做解析。
这种方法虽然可以比较好地接收数据,在单片机下很好用。但是在这里,相同的线程挂起时间情况下,每次uart_read只获取一个字节,这样会损耗一定的接收效率,有点拆东墙补西墙的感觉。在我们这边的应用中,与算法所需的时序要求有冲突了,所以只能再想想其它方法。下面看看方法三。
方法三:时间戳法
这种方法需要明确每一帧数据包含有什么数据,以及数据输出的频率是多少。在相同的线程挂起时间情况下,先把用于uart_read接收数据的buffer设置得稍微大一点,看每一次最多能读取到多少个字节得数据以及读完一帧数据需要读几次串口数据。然后我们可以通过时间来区分每一帧数据及每一包串口数据,该重新组包的就重新组包。
例如:每帧数据间隔200ms,线程挂起时间10ms,一帧数据有130字节,一帧数据由1包、2包串口数据组成,可以通过时间戳来判断每一包之间是数据帧之间的间隔还是每一帧数据里的两个数据包之间的间隔,再做相应的逻辑处理即可很好地接收数据。
GPS数据解析
gps数据怎么解析呢?
方法可能很多,我们先看一下正点原子的解析方法:
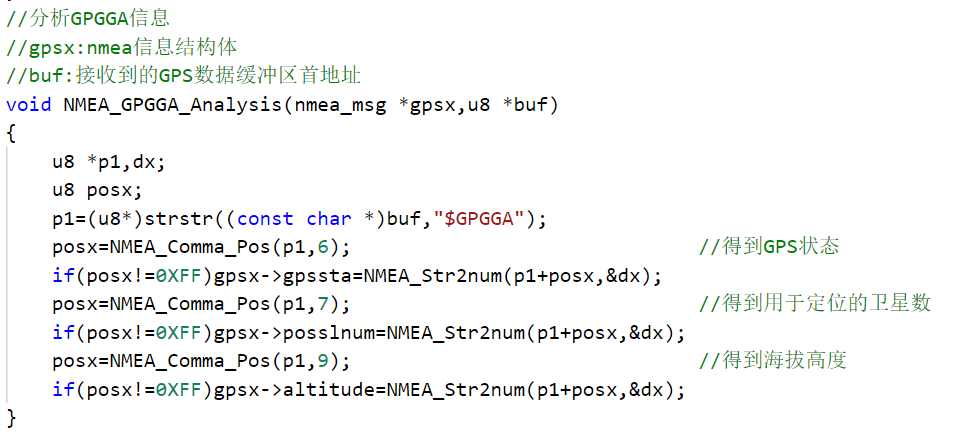

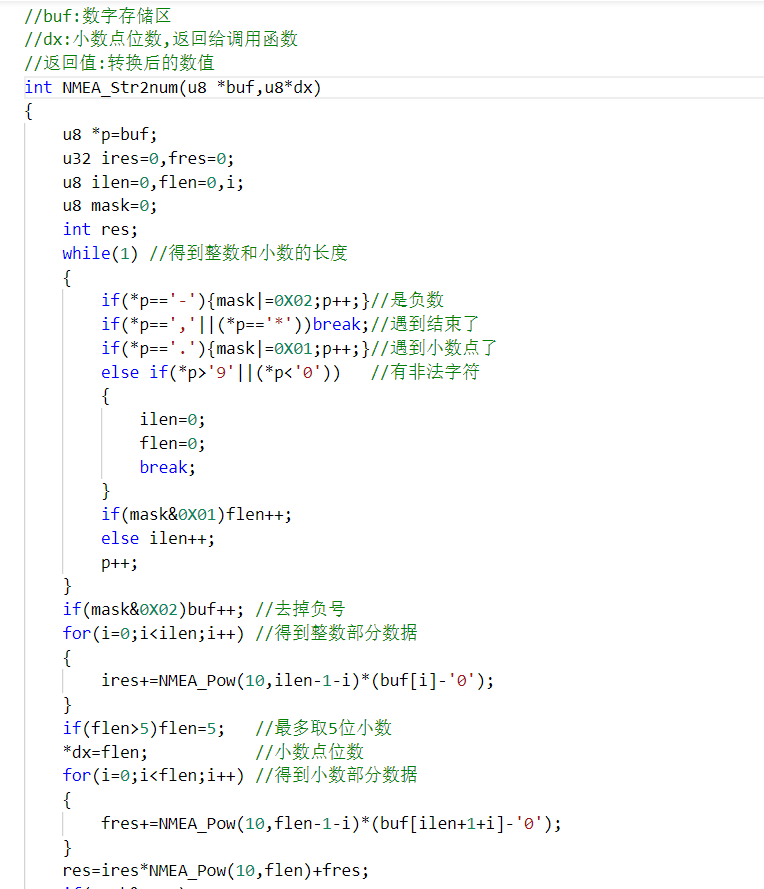
大概分为两步,第一步先获取逗号的位置确定某个需要解析的字段,然后再将相应字段的字符串数据转换成数字。
这里分享一种简单实用的解析方法,思路与上面差不多,但是相对比较简单清晰些:
static bool gps_gga_data_parse(st_gps_gga_def *out_data, char *in_data)
{
bool ret = FALSE;
char *p_gga = in_data;
if (NULL == p_gga)
{
return ret;
}
if (NULL != (p_gga = strstr(p_gga, "$GNGGA")))
{
printf("gga data : %s\n", p_gga);
/* 数据校验 */
if (TRUE == data_check(p_gga))
{
printf("gga data check success!\n");
/* 解析出字符串 */
printf("gga data parse: \n");
for (int i = 0; i < GGA_STR_MAX; i++)
{
sscanf(p_gga, "%[^,]", gps_gga_str[i]);
printf("%s\n", gps_gga_str[i]);
p_gga = p_gga + (strlen(gps_gga_str[i]) + 1);
}
/* 字符串转数字 */
out_data->latitude = atof(gps_gga_str[STR_LATITUDE]);
out_data->longitude = atof(gps_gga_str[STR_LONGITUDE]);
out_data->time = atof(gps_gga_str[STR_TIME]);
out_data->quality = atof(gps_gga_str[STR_QUALITY]);
ret = TRUE;
}
else
{
printf("gga data check error!\n");
}
}
return ret;
}这里使用sscanf+正则表达式来做解析。
sscanf(p_gga, "%[^,]", gps_gga_str[i]);sscanf函数在做字符串相关解析时很好用,这里配合正则表达式来使用,上面这一句代码的意思就是从p_gga中取逗号前面的数据存放到gps_gga_str[i]中,因为gga数据都是用逗号隔开的,循环几次就可以把所有数据解析出来,很方便。
正则表达式学习资源如:
1、https://deerchao.cn/tutorials/regex/regex.htm
2、https://www.runoob.com/regexp/regexp-syntax.html下面再看一下,sscanf+正则表达式的几种简单用法:
1、取指定长度的字符串。
如在下例中,取最大长度为4字节的字符串。
sscanf("123456 ", "%4s", str);2、 取到指定字符为止的字符串。
如在下例中,取遇到空格为止字符串。
sscanf("123456 abcdedf", "%[^ ]", str);3、取仅包含指定字符集的字符串。
如在下例中,取仅包含1到9和小写字母的字符串。
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", str);4、取到指定字符集为止的字符串。
如在下例中,取遇到大写字母为止的字符串。
scanf("123456abcdedfBCDEF", "%[^A-Z]", str);sscanf+简单、易理解的正则表达式的方法有时候可以帮助我们很方便地进行字符串数据地解析。sscanf+复杂的正则表达式不太建议使用,因为代码可读性太差了。
另外,使用sscanf+正则表达式时有必要写点注释,有见过这种方式还好,有些后面看你代码的人可能没接触过正则表达式可能一时半会儿理解不了。我之前大三出去实习的时候,在公司里就看到这样的代码,那时候知识储备还不够,第一次看到sscanf+正则表达式这种解析方法,但是搜索又搜索不到相关答案,很苦恼。所以,平时有必要写一些注释,利人利己。
参考:
1、正点原子《ATK-NEO-6M GPS模块》资料。
2、https://blog.csdn.net/absurd/article/details/1177092




